The rapid integration of Large Language Models (LLMs) into the enterprise landscape has opened unprecedented avenues for innovation. However, this powerful new technology also brings a unique set of challenges. To ensure the successful deployment and sustained value of LLM-powered applications, organizations need robust monitoring, diagnostic, and security strategies. This article explores a comprehensive approach to LLM observability, from infrastructure performance to output reliability, and highlights best practices for a holistic management framework.
The Foundation of Observability: Unifying Infrastructure and Application Insights
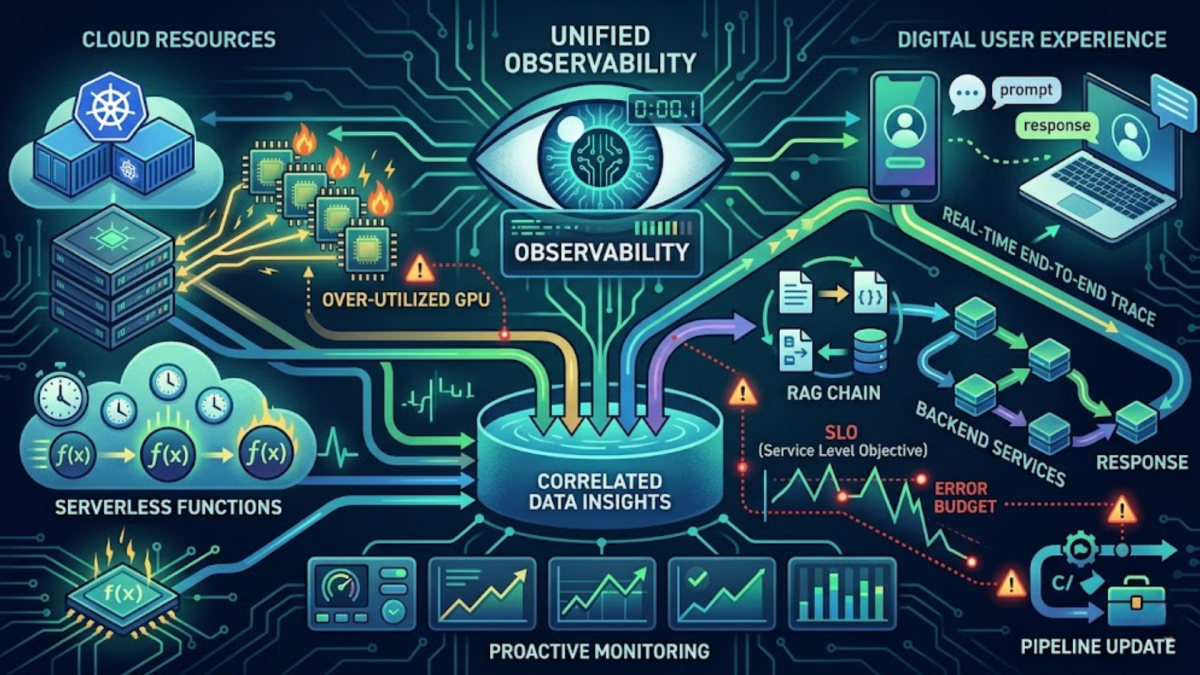
The path to optimized LLM application deployment begins with a unified visibility framework. A powerful LLM on its own is insufficient, it must operate efficiently within its underlying infrastructure. This section emphasizes the critical role of enterprise-grade observability tools that can simultaneously track the performance of cloud resources, such as Kubernetes clusters and GPU instances and the real-time dynamics of digital user experiences. By correlating serverless function metrics with the end-to-end trace of a user’s prompt through various services (a RAG chain, for example), teams can swiftly pinpoint whether an application slowdown stems from a complex software delivery pipeline update or an over-utilized backend service. This proactive monitoring approach provides the data-driven clarity needed to maintain responsive and resilient AI-driven solutions.
Securing the Frontier: Best Practices for Prompt Integrity and Multi-Step Workflows
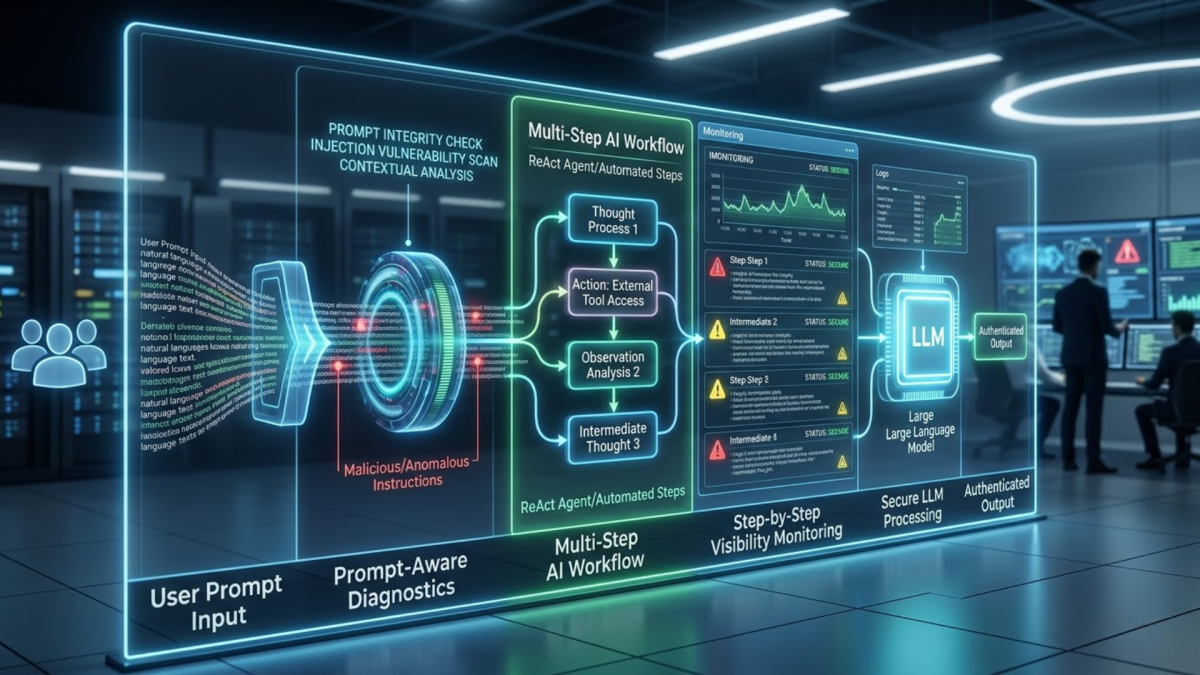
As LLM applications become more sophisticated, they introduce new and unique security vectors. Unlike traditional software with well-defined inputs, the open-ended nature of user interaction with an LLM makes it susceptible to a class of vulnerabilities known as prompt injection attacks. This section details why standard security practices are no longer sufficient. It advocates for integrated diagnostics that are "prompt-aware," designed to inspect the actual natural language instructions being processed by the model. Furthermore, as organizations deploy more complex multi-step AI workflows (e.g., using ReAct agents or other automated agents), the potential points of failure and security compromises increase exponentially. Effective management requires not just looking at the final output, but gaining deep visibility into each intermediate step of the chain, ensuring integrity and preventing malicious actors from hijacking the AI to perform unauthorized actions.
Ensuring Excellence: AI-Driven Diagnostics for Output Reliability and Data Quality
The final pillar of a robust LLM management strategy moves beyond technical metrics like latency and uptime to focus on the value and trustworthiness of the model’s conversational outputs. Traditional quality assurance cannot easily adapt to the probabilistic and subjective nature of LLM responses. This section explains how organizations are utilizing specialized, AI-driven diagnostics to ensure output reliability and maintain high-quality data. These advanced techniques involve automatically evaluating responses for factuality, tone, hallucination rates, and compliance with organizational guidelines. By monitoring for concept drift and tracking performance degradation in production, teams can maintain a feedback loop that identifies when a model requires finetuning or retraining. This approach transforms LLM observability from a passive monitoring task into an active quality assurance program, guaranteeing that AI initiatives deliver consistently accurate, helpful, and safe information.

Conclusion: The Integrated Platform Advantage
Successfully navigating the LLM frontier requires moving away from fragmented, siloed monitoring tools toward an integrated observability platform. By combining infrastructure insights, specialized security analytics, and AI-driven diagnostics under a single pane of glass, organizations gain a holistic understanding of their AI deployments. This comprehensive approach enables teams to troubleshoot performance issues in minutes, proactively defend against novel security threats, and maintain unwavering trust in the quality and reliability of AI-generated insights. Ultimately, establishing this integrated visibility is not just about technical maintenance; it is the critical prerequisite for unlocking the full transformative potential of Large Language Models within the modern enterprise.